

Дискретно-стохастические модели (Р-схемы).
При дискретно-стохастическом подходе к формализации процесса функционирования системы S подход остается аналогичный рассмотренному конечному автомату, то влияние фактора стохастичности можно проследить разновидности таких автоматов, а именно на вероятностных (стохастических) автоматах.
В общем виде вероятностный автомат (англ. probabilistic automat) можно определить как дискретный потактный преобразователь информации с памятью, функционирование которого в каждом такте зависит только от состояния памяти в нем и может быть описано статистически.
Применение схем вероятностных автоматов (Р - схем) имеет важное значение для разработки методов проектирования дискретных систем, проявляющих статистически закономерное случайное поведение, для выяснения алгоритмических возможностей таких систем и обоснования границ целесообразности их использования, а также для решения задач синтеза по выбранному критерию дискретных стохастических систем, удовлетворяющих заданным ограничениям.
множество G, элементами которого являются всевозможные пары 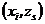 , где хi и zs —-элементы входного подмножества X и подмножества состояний Z соответственно. Если существуют две такие функции j и y, то с их помощью осуществляются отображения
, где хi и zs —-элементы входного подмножества X и подмножества состояний Z соответственно. Если существуют две такие функции j и y, то с их помощью осуществляются отображения 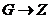 и
и 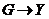 , то говорят, что
, то говорят, что 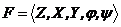 определяет автомат детерминированного типа.
определяет автомат детерминированного типа.
Введем в рассмотрение более общую математическую схему. Пусть Ф — множество всевозможных пар вида 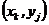 , где yj — элемент выходного подмножества Y. Потребуем, чтобы любой элемент множества G индуцировал на множестве Ф некоторый закон распределения следующего вида:
, где yj — элемент выходного подмножества Y. Потребуем, чтобы любой элемент множества G индуцировал на множестве Ф некоторый закон распределения следующего вида:
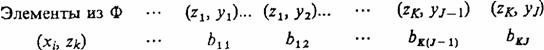
При этом 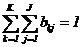 , где bkj — вероятности перехода автомата в состояние zkи появления на выходе сигнала yj если он был в состоянии zs и на его вход в этот момент времени поступил сигнал xi. Число таких распределений, представленных в виде таблиц, равно числу элементов множества G. Обозначим множество этих таблиц через В. Тогда четверка элементов
, где bkj — вероятности перехода автомата в состояние zkи появления на выходе сигнала yj если он был в состоянии zs и на его вход в этот момент времени поступил сигнал xi. Число таких распределений, представленных в виде таблиц, равно числу элементов множества G. Обозначим множество этих таблиц через В. Тогда четверка элементов  называется вероятностным автоматом (Р - автоматом).
называется вероятностным автоматом (Р - автоматом).
Пусть элементы множества G индуцируют некоторые законы распределения на подмножествах Y и Z, что можно представить соответственно в виде:
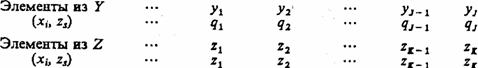
При этом 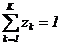 и
и 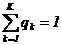 где zk и qk — вероятности перехода Р-автомата в состояние zk и появления выходного сигнала уk при условии, что Р-автомат находился в состоянии zs и на его вход поступил входной сигнал хi.
где zk и qk — вероятности перехода Р-автомата в состояние zk и появления выходного сигнала уk при условии, что Р-автомат находился в состоянии zs и на его вход поступил входной сигнал хi.
Если для всех k и j имеет место соотношение  , то такой Р-автомат называется вероятностным автоматом Мили. Это требование означает выполнение условия независимости распределений для нового состояния Р-автомата и его выходного сигнала.
, то такой Р-автомат называется вероятностным автоматом Мили. Это требование означает выполнение условия независимости распределений для нового состояния Р-автомата и его выходного сигнала.
определение выходного сигнала Р-автомата зависит лишь от того состояния, в котором находится автомат в данном такте работы. Другими словами, пусть каждый элемент выходного подмножества Y индуцирует распределение вероятностей выходов, имеющее следующий вид:
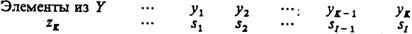
Здесь 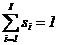 , где si — вероятность появления выходного сигнала yi при условии, что Р-автомат находился в состоянии zk.
, где si — вероятность появления выходного сигнала yi при условии, что Р-автомат находился в состоянии zk.
для всех k и i имеет место соотношение 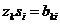 , то такой Р-автомат называется вероятностным автоматом Мура.
, то такой Р-автомат называется вероятностным автоматом Мура.
Понятие Р-автоматов Мили и Мура введено по аналогии с детерминированным F-автоматом, задаваемым 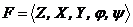 . Частным случаем Р-автомата, задаваемого как
. Частным случаем Р-автомата, задаваемого как 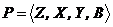 являются автоматы, у которых либо переход в новое состояние, либо выходной сигнал определяются детерминированно. Если выходной сигнал Р-автомата определяется детерминированно, то такой автомат называется Y-детерминированным вероятностным автоматом. Аналогично, Z-детерминированным вероятностным автоматом называется Р-автомат, у которого выбор нового состояния является детерминированным.
являются автоматы, у которых либо переход в новое состояние, либо выходной сигнал определяются детерминированно. Если выходной сигнал Р-автомата определяется детерминированно, то такой автомат называется Y-детерминированным вероятностным автоматом. Аналогично, Z-детерминированным вероятностным автоматом называется Р-автомат, у которого выбор нового состояния является детерминированным.
Y-детерминированный Р-автомат задаётся таблицей переходов и таблицей выходов. Первую из этих таблиц можно представить в виде квадратной матрицы размерности К´К, которую будем называть матрицей переходных вероятностей или просто матрицей переходов Р-автомата. В общем случае такая матрица переходов имеет вид
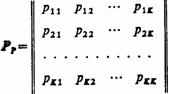
Для описания Y-детерминированного Р-автомата необходимо задать начальное распределение вероятностей вида

Здесь dk — вероятность того, что в начале работы Р-автомат находится в состоянии k. При этом 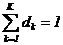 .
.
Y-детерминированный Р-автомат можно задать в виде ориентированного графа, вершины которого сопоставляются состояниям автомата, а дуги — возможным переходам из одного состояния в другое. Дуги имеют веса, соответствующие вероятностям перехода рij, а около вершин графа пишутся значения выходных сигналов, индуцируемых этими состояниями рис 1.
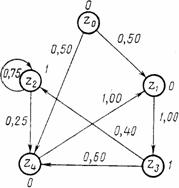
рис 1.
Р-автоматы могут использоваться как генераторы марковскихпоследовательностей, которые необходимы при построении и реализации процессов функционирования систем S или воздействий внешней среды Е.
Для оценки различных характеристик исследуемых систем, представляемых в виде Р-схем, кроме случая аналитических моделей можно применять и имитационные модели, реализуемые, например, методом статистического моделирования.
Особенности фиксации и статистической обработки результатов моделирования систем на ЭВМ.
При выборе методов обработки существенную роль играют три особенности машинного эксперимента с моделью системы S.
1. Возможность получать при моделировании системы S на ЭВМ большие выборки позволяет количественно оценить характеристики процесса функционирования системы, но превращает в серьезную проблему хранение промежуточных результатов моделирования. Эту проблему можно решить, используя рекуррентные алгоритмы обработки, когда оценки вычисляют по ходу моделирования.
2. Сложность исследуемой системы S при ее моделировании на ЭВМ часто приводит к тому, что априорное суждение о характеристиках процесса функционирования системы, например о типе ожидаемого распределения выходных переменных, является невозможным. Поэтому при моделировании систем широко используются непараметрические оценки и оценки моментов распределения.
3. Блочность конструкции машинной модели Мм и раздельное исследование блоков связаны с программной имитацией входных переменных для одной частичной модели по оценкам выходных переменных, полученных на другой частичной модели. Если ЭВМ, используемая для моделирования, не позволяет воспользоваться переменными, записанными на внешние носители, то следует представить эти переменные в форме, удобной для построения алгоритма их имитации.
При исследовании сложных систем и большом числе реализаций N в результате моделирования на ЭВМ получается значительный объем информации о состояниях процесса функционирования системы. Поэтому необходимо так организовать в процессе вычислений фиксацию и обработку результатов моделирования, чтобы оценки для искомых характеристик формировались постепенно по ходу моделирования, т. е. без специального запоминания всей информации о состояниях процесса функционирования системы S.
Если при моделировании процесса функционирования конкретной системы S учитываются случайные факторы, то и среди результатов моделирования присутствуют случайные величины. В качестве оценок для искомых характеристик рассчитывают средние значения, дисперсии, корреляционные моменты и т. д.
при обработке результатов моделирования можно подойти к оценке вероятностей возможных значений случайной величины, т. е. закона распределения. Область возможных значений случайной величины h разбивается на п интервалов. Затем накапливается количество попаданий случайной величины в эти интервалы тk, к=1, п. Оценкой для вероятности попадания случайной величины в интервал с номером k служит величина mk/N. Таким образом, при этом достаточно фиксировать пзначений тk при обработке результатов моделирования на ЭВМ.
Для оценки среднего значения случайной величины h накапливается сумма возможных значений случайной величины уk, k=1,N, которые она принимает при различных реализациях. Тогда среднее значение
.
При этом ввиду несмещенности и состоятельности оценки
;
.
В качестве оценки дисперсии случайной величины h при обработке результатов моделирования можно использовать
При обработке результатов машинного эксперимента с моделью Мм наиболее часто возникают следующие задачи: определение эмпирического закона распределения случайной величины, проверка однородности распределений, сравнение средних значений и дисперсий переменных, полученных в результате моделирования, и т. д. Эти задачи с точки зрения математической статистики являются типовыми задачами по проверке статистических гипотез.
Задача определения эмпирического закона распределения случайной величины наиболее общая из перечисленных, но для правильного решения требует большого числа реализаций N. В этом случае по результатам машинного эксперимента находят значения выборочного закона распределения Fэ(y) (или функции плотности fэ(y)) и выдвигают нулевую гипотезу Н0,что полученное эмпирическое распределение согласуется с каким-либо теоретическим распределением. Проверяют эту гипотезу Н0 с помощью статистических критериев согласия Колмогорова, Пирсона, Смирнова и т. д., причем необходимую в этом случае статистическую обработку результатов ведут по возможности в процессе моделирования системы S на ЭВМ.
Критерий согласия Колмогорова основан на выборе в качестве меры расхождения U величины .
Из теоремы Колмогорова следует, что при имеет функцию распределения
Если вычисленное на основе экспериментальных данных значение 5 меньше, чем табличное значение при выбранном уровне значимости у, то гипотезу Я0 принимают, в противном случае расхождение между Fэ(y) и F(y) считается неслучайным гипотеза Н0 отвергается.
Критерий Колмогорова для обработки результатов моделирования целесообразно применять в тех случаях, когда известны все параметры теоретической функции распределения. Недостаток использования этого критерия связан с необходимостью фиксации в памяти ЭВМ для определения D всех статистических частот с целью их упорядочения в порядке возрастания.
Критерий согласия Пирсона основан на определении в качестве меры расхождения U величины
,
где тi — количество значений случайной величины h, попавших в i-й подынтервал; pi — вероятность попадания случайной величины h в i-й подынтервал, вычисленная из теоретического распределения; d — количество подынтервалов, на которые разбивается интервал измерения в машинном эксперименте.
При закон распределения величины U, являющейся мерой расхождения, зависит только от числа подынтервалов и приближается к закону распределения (хи-квадрат) с (d-r-1) степенями свободы, где r — число параметров теоретического закона распределения.
Из теоремы Пирсона следует, что, какова бы ни была функция распределения F(y) случайной величины h, при распределение величины имеет вид
где Г(k/2) — гамма-функция; z — значение случайной величины , k = d-r-1 — число степеней свободы. Функции распределенияFk(z) табулированы.
По вычисленному значению U= и числу степеней свободы k с помощью таблиц находится вероятность .Если эта вероятность превышает некоторый уровень значимости , то считается, что гипотеза Н0 о виде распределения не опровергается результатами машинного эксперимента.
Для принятия или опровержения гипотезы выбирают некоторую случайную величину U, характеризующую степень расхождения теоретического и эмпирического распределения, связанную с недостаточностью статистического материала и другими случайными причинами. Закон распределения этой случайной величины зависит от закона распределения случайной величины h и числа реализаций N при статистическом моделировании системы S. Если вероятность расхождения теоретического и эмпирического распределений Р